
우아한테크코스 레벨 4 팀 프로젝트 festabook에서 학습한 내용을 정리한 글입니다.
💭 들어가며
이전 글에서 이론적인 관점에서 인덱스를 살펴보았고, 이번 글에서는 MySQL(InnoDB)을 기준으로 인덱스의 실제 종류와 실행 계획을 분석했다. 직접 쿼리를 실행해 동작을 검증하고, 그 결과를 토대로 인덱스의 실제 동작 원리를 정리해 보았다.
✅ MySQL(InnoDB) 구조
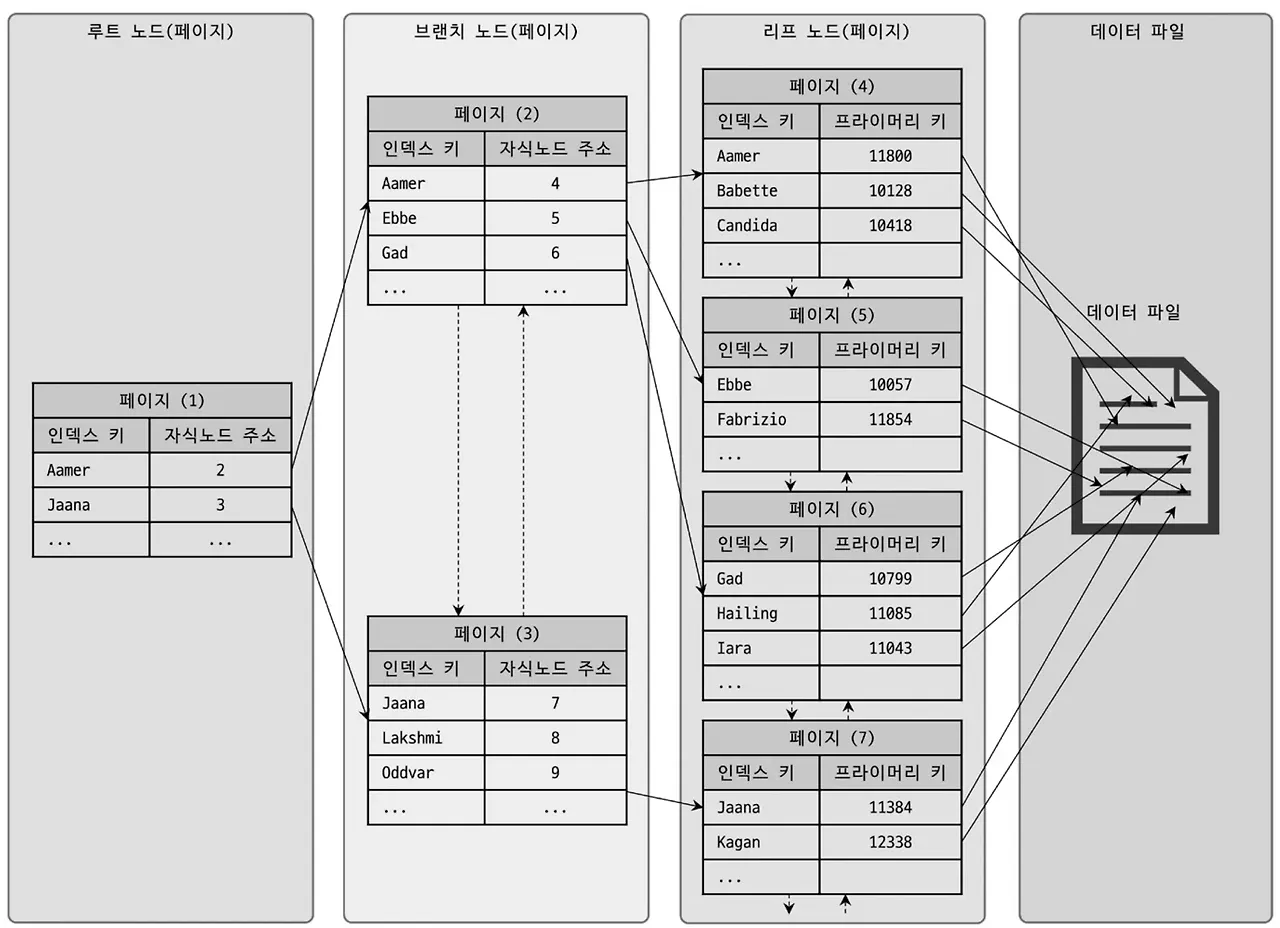
MySQL(InnoDB)는 데이터를 B-Tree 구조로 저장한다. 이때 Secondary Index의 리프 노드에는 실제 데이터가 아닌 해당 레코드의 Primary Key 값이 저장되어 있으며, 실제 데이터는 Primary Key를 기준으로 한 B-Tree 구조의 데이터 파일에 따로 저장된다.
이러한 구조를 클러스터링 인덱스(Clustering Index)라고 한다. 클러스터링 인덱스의 특징을 간단히 정리하면, 읽기(SELECT)는 빠르지만 쓰기(INSERT, UPDATE, DELETE)는 느리다는 점이다. Real MySQL 8.0에 따르면, 일반적인 온라인 트랜잭션 처리 환경(OLTP, Online Transaction Processing)에서는 읽기와 쓰기의 비율이 약 8:2 또는 9:1 정도이므로, 다소 느린 쓰기 성능을 감수하더라도 빠른 읽기 성능을 확보하는 것이 훨씬 중요하다고 한다.
🔽 참고
여기서 B-Tree란 Binary Tree(이진 트리)가 아니라, Balanced Tree(균형 트리)를 의미한다.
🔽 참고
MySQL은 데이터를 한 곳에 연속된 공간에 저장하지 않고, 페이지(Page) 단위로 나누어 저장한다. 페이지의 기본 크기는 16KB이다.
✅ MySQL(InnoDB) 인덱스
▶ Primary Key (기본 키 인덱스)

테이블의 기본 키(Primary Key)에 대해 생성되는 인덱스이다.
- InnoDB에서는 기본 키 인덱스가 클러스터링 인덱스(Clustering Index)로 저장되며, 이는 테이블의 실제 데이터가 기본 키 순서대로 정렬되어 저장됨을 의미한다.
- 하나의 테이블에는 Primary Key가 하나만 존재할 수 있다.
- PK 인덱스의 리프 노드에 실제 데이터(Row)가 함께 저장된다. (즉, 인덱스 = 데이터 파일)
- Primary Key를 변경하면 실제 데이터 재배치가 발생하므로 매우 비용이 큰 연산이다.
🔽 예시 코드
CREATE TABLE users (
id BIGINT PRIMARY KEY AUTO_INCREMENT, -- Primary Key
email VARCHAR(255)
);
ALTER TABLE users ADD PRIMARY KEY (id);🔽 SHOW INDEX 결과

▶ Unique Index (유니크 인덱스)
특정 컬럼의 값이 중복되지 않도록 보장하는 인덱스이다.
- 같은 값을 가진 행이 두 번 이상 저장되지 않도록 제약조건을 부여한다.
- NULL 값은 여러 개 허용된다. (MySQL에서는 NULL을 서로 다른 값으로 취급)
- 중복된 값이 삽입될 경우 Duplicate entry 오류가 발생한다.
- WHERE 조건에서 = 비교를 사용할 경우, const 수준의 빠른 접근 방식이 가능하다.
🔽 예시 코드
CREATE TABLE members (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(255) UNIQUE -- Unique Index
);
CREATE UNIQUE INDEX unique_index_email ON users (email);🔽 SHOW INDEX 결과

▶ Index (Secondary Index) (보조 인덱스)

기본 키 외의 컬럼에 대해 검색 성능을 높이기 위해 사용하는 일반적인 인덱스이다.
- 여러 행이 동일한 인덱스 값을 가질 수 있다. (중복 허용)
- 리프 노드에 PK 값을 저장하고, 이를 통해 실제 데이터를 찾아간다.
- 검색 조건(WHERE절)에 자주 등장하는 컬럼에 생성하면 효율적이다.
- 쓰기 연산 시, 모든 보조 인덱스를 함께 갱신해야 하므로 오버헤드가 발생한다.
- Primary Key 인덱스와는 별개로, Secondary Index + Primary Key 구조의 B-Tree가 생성된다.
🔽 예시 코드
CREATE TABLE orders (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id BIGINT,
INDEX idx_user_id (user_id) -- Secondary Index
);
CREATE INDEX idx_user_id ON orders (user_id);🔽 SHOW INDEX 결과

▶ Composite Index (복합 인덱스)
두 개 이상의 컬럼으로 구성된 인덱스이다.
- 선두 컬럼을 기준으로 정렬되며 Leftmost Prefix Rule이 적용된다.
- 범위 조건이 선두 컬럼에 등장하면, 그 뒤 컬럼은 인덱스 순서상의 추가 정렬/필터링에 제한이 생길 수 있다.
- MySQL 8.0의 Skip Scan이 유리하다고 판단될 때만 예외적으로 선두 컬럼 없이도 복합 인덱스를 사용할 수 있다(카디널리티 등 조건 충족 시).
🔽 예시 코드
CREATE TABLE products (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
category_id INT,
brand_id INT,
price INT,
INDEX idx_category_brand (category_id, brand_id) -- Composite Index
);
CREATE INDEX idx_category_brand ON products (category_id, brand_id);🔽 SHOW INDEX 결과

🔽 EXPLAIN 결과



- brand_id는 선두 컬럼이 아니므로, 본 실행 계획에서는 복합 인덱스가 선택되지 않아 테이블 풀 스캔(type = ALL)이 발생한다.
🔽 참고
EXPLAIN은 옵티마이저가 쿼리를 어떻게 탐색할지에 대한 실행 계획을 보여준다. 이때 type = ALL은 Table Full Scan을 의미한다. (아래에서 자세히 설명)
▶ Full-Text Index (전문 검색 인덱스)
긴 문자열 컬럼(TEXT, VARCHAR)에 대해 자연어 기반의 전문 검색을 수행할 수 있는 인덱스이다.
- LIKE '%keyword%'보다 훨씬 빠른 문자열 검색 성능을 제공한다.
- MATCH(...) AGAINST(...) 문법을 사용해 검색을 수행한다.
- InnoDB 엔진에서는 MySQL 5.6부터 지원한다.
- 검색 모드
- NATURAL LANGUAGE: 기본 자연어 모드
- BOOLEAN: AND/OR, +, - 등 논리 연산자 활용
- QUERY EXPANSION: 연관어 확장 검색
- 영어 외 언어(한글 등)를 검색하려면 ngram parser를 설정해야 한다.
🔽 참고
MySQL의 Full-Text Index는 크게 어근 분석 알고리즘과 n-gram 알고리즘 두 가지 방식으로 동작한다. 어근 분석 알고리즘은 언어마다 문법 구조와 형태소 체계가 달라, 언어별로 별도의 설정이 필요하다. 반면 n-gram 알고리즘은 언어의 문법적 이해 없이도 적용할 수 있어 언어 독립적이라는 장점이 있지만, 그만큼 인덱스 크기가 커지는 단점이 있다.
🔽 예시 코드
CREATE TABLE articles (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(255),
content TEXT,
FULLTEXT INDEX idx_fulltext_content (title, content) -- Full-Text Index
);
CREATE FULLTEXT INDEX idx_fulltext_content ON articles (title, content) WITH PARSER ngram;-- 사용 예시
SELECT * FROM articles WHERE MATCH(title, content) AGAINST('미소' IN NATURAL LANGUAGE MODE);🔽 SHOW INDEX 결과

🔽 EXPLAIN 결과

▶ Spatial Index (공간 인덱스)

공간 데이터(GEOMETRY, POINT 등)를 효율적으로 검색하기 위해 사용되는 R-Tree 기반 인덱스이다.
- R-Tree 인덱스 알고리즘을 사용하여 2차원 공간 데이터를 인덱싱하고 탐색한다.
- 주로 ST_Distance, MBRWithin, MBRContains 등의 GIS 함수와 함께 사용된다.
- InnoDB 엔진에서는 NOT NULL 제약조건이 반드시 필요하다.
🔽 예시 코드
CREATE TABLE locations (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
position POINT NOT NULL SRID 4326,
SPATIAL INDEX idx_position (position) -- Spatial Index
);
CREATE SPATIAL INDEX idx_position ON locations (position);-- 사용 예시
SELECT * FROM locations WHERE MBRContains(ST_GeomFromText('POLYGON((35 126,38 126,38 130,35 130,35 126))', 4326), position);🔽 SHOW INDEX 결과

🔽 EXPLAIN 결과

▶ Functional Index (함수 기반 인덱스) (8.0.13+)
컬럼에 함수를 적용한 결과에 생성하는 인덱스이다.
- 일반적으로 WHERE 절에서 함수가 사용되면 인덱스가 무효화되는 문제를 해결한다.
- ((expression)) 형태로 생성한다.
- 내부적으로 가상 컬럼 기반으로 동작한다.
- 단일 컬럼뿐 아니라 여러 컬럼을 조합한 표현식에도 인덱스를 적용할 수 있다.
🔽 예시 코드
CREATE TABLE logs (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
created_at DATETIME,
message VARCHAR(255),
INDEX idx_date ((DATE(created_at))) -- Functional Index
);
CREATE INDEX idx_date ON logs ((DATE(created_at)));-- 사용 예시
SELECT * FROM logs WHERE DATE(created_at) = '2025-01-01';🔽 SHOW INDEX 결과

🔽 EXPLAIN 결과

▶ Multi-Valued Index (다중 값 인덱스) (8.0.17+)
JSON 배열 컬럼 내부 값들에 대해 생성하는 인덱스이다.
- 배열의 각 원소가 인덱스의 개별 엔트리로 저장되어, JSON 필드 내부 값에 대한 직접 검색이 가능해진다.
- 인덱스 생성 시 ARRAY 캐스팅 문법을 사용해야 한다.
- 범위 검색은 불가능하며, 정확한 일치 검색만 지원한다.
🔽 참고
Real MySQL 8.0에 따르면 최근 RDBMS들이 JSON 데이터 타입을 공식적으로 지원하기 시작하면서, JSON 배열 컬럼에 저장된 각 원소에 대해서도 인덱싱이 가능해졌다. 초기에는 JSON 필드에 인덱스를 적용할 수 없어 MongoDB와 자주 비교되었지만, 현재는 MySQL 역시 JSON 배열 단위 인덱스를 완벽히 지원하는 수준에 이르렀다.
🔽 예시 코드
CREATE TABLE books (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(100),
tags JSON,
INDEX idx_tags ((CAST(tags AS CHAR(100) ARRAY))) -- Multi-Valued Index
);
CREATE INDEX idx_tags ON books ((CAST(tags AS CHAR(100) ARRAY)));-- 사용 예시
SELECT * FROM books WHERE JSON_CONTAINS(tags, '"database"');🔽 SHOW INDEX 결과

🔽 EXPLAIN 결과

▶ Foreign Key (외래 키 인덱스)
참조 무결성을 보장하기 위한 인덱스이다.
- InnoDB 스토리지 엔진에서만 지원된다.
- 외래 키 제약을 추가하면 연관된 컬럼에 인덱스가 자동으로 생성된다.
- 자동 생성된 인덱스는 외래 키 제약을 제거하지 않으면 삭제할 수 없다.
- 참조 대상 컬럼(FK)은 반드시 인덱스를 가져야 한다.
- Primary Key 인덱스와는 별도로, Foreign Key + Primary Key 구조의 B-Tree가 별도로 생성된다.
🔽 예시 코드
CREATE TABLE departments (
id BIGINT PRIMARY KEY,
name VARCHAR(100)
);
CREATE TABLE employees (
id BIGINT PRIMARY KEY,
dept_id BIGINT,
FOREIGN KEY (dept_id) REFERENCES departments(id)
);
ALTER TABLE employees
ADD CONSTRAINT fk_employees_department
FOREIGN KEY (dept_id)
REFERENCES departments(id);🔽 SHOW INDEX 결과

✅ 테이블 스캔 종류
▶ Index Range Scan


인덱스의 일부 구간(range)만 탐색하는 방식이다.
- BETWEEN, <, >, IN, LIKE 'abc%' 등 범위 조건이 있을 때 발생한다.
- 옵티마이저는 key_len을 통해 실제 사용된 인덱스 길이를 계산한다.
- 범위 조건이 넓을수록 읽는 범위가 커져 성능이 저하될 수 있다.
- 시간 복잡도는 O(log N + M)이다.
- log N: 인덱스 트리에서 첫 위치 탐색
- M: 범위 내 레코드 스캔 수
- EXPLAIN
- type: range, ref, ref_or_null, index_subquery
🔽 예시 코드
CREATE TABLE orders (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
price INT,
INDEX idx_price (price)
);-- 사용 예시
SELECT * FROM orders WHERE price BETWEEN 1000 AND 5000;🔽 EXPLAIN 결과

▶ Index Full Scan
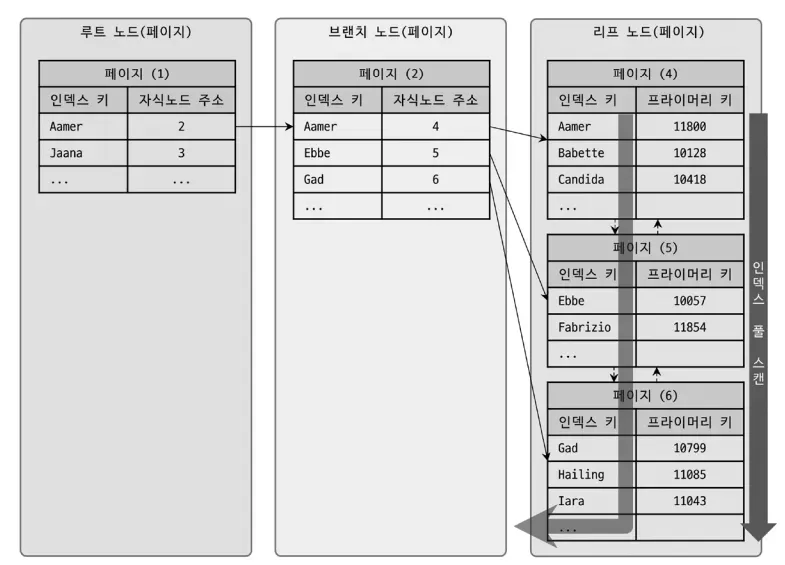
인덱스의 전체를 순차적으로 스캔하는 방식이다.
- 테이블을 직접 읽지 않고, 인덱스 리프 노드를 모두 탐색한다.
- 조회 대상이 인덱스에 포함된 컬럼만이라면, 커버링 인덱스(Using index)로 동작한다.
- 인덱스가 정렬된 구조이므로, ORDER BY 최적화에도 사용될 수 있다.
- 시간 복잡도는 O(N)이다.
- N: 인덱스 엔트리 수
- EXPLAIN
- type: index
- Extra: Using index
🔽 예시 코드
CREATE TABLE users (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(255),
INDEX idx_email (email)
);-- 사용 예시: 인덱스 전체 탐색
SELECT email FROM users;
-- 사용 예시: 인덱스로 정렬 최적화
SELECT email FROM users ORDER BY email;🔽 EXPLAIN 결과

▶ Loose Index Scan

인덱스의 일부 키만 선택적으로 읽고, 불필요한 키들은 인덱스 구조를 건너뛰며 탐색하는 방식이다.
- 필요하지 않은 인덱스 키를 건너뛰며 최소한의 엔트리만 읽는다.
- GROUP BY, MIN(), MAX() 등의 집계 연산 시 사용된다.
- 인덱스의 정렬 순서가 GROUP BY 순서와 동일해야 동작한다.
- 불필요한 중복 키를 생략하므로 읽기 비용을 절감할 수 있다.
- 시간 복잡도는 O(log N + G)이다.
- log N: 인덱스 탐색 비용
- G: 그룹 개수
- EXPLAIN
- type: range (특정 상황에서)
- Extra: Using index for group-by
🔽 예시 코드
CREATE TABLE sales (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
year INT,
month INT,
amount INT,
INDEX idx_year_amount (year, amount)
);-- 사용 예시: 연도별로 첫 번째 행(최소 금액)을 읽음
SELECT year, MIN(amount) FROM sales GROUP BY year;🔽 EXPLAIN 결과

▶ Index Skip Scan (8.0+)

복합 인덱스에서 선두 컬럼 조건이 없어도 옵티마이저가 내부적으로 선두 컬럼의 고유값을 반복 탐색하여 후행 컬럼 조건만으로 인덱스를 활용할 수 있게 하는 방식이다.
- 옵티마이저가 선두 컬럼의 모든 고유값에 대해 내부적으로 부분 인덱스 스캔을 반복 수행한다.
- 선두 컬럼의 카디널리티가 낮고, 후행 컬럼의 선택도가 높을 때 효과적이다.
- 시간 복잡도는 O(K × log N)이다.
- K: 선두 컬럼의 고유값 개수
- log N: 각 고유값에 대한 인덱스 탐색 비용
- EXPLAIN
- type: range
- Extra: Using index skip scan
🔽 참고
실제로 옵티마이저가 Index Skip Scan을 선택하는 조건은 상당히 까다롭다. 단순히 테이블 구조나 쿼리 형태만으로는 활성화되지 않으며, 여러 최적화 조건이 동시에 충족되어야 한다. 다음은 옵티마이저가 Skip Scan을 선택하기 위한 주요 조건들이다.
- 인덱스의 선두 컬럼의 카디널리티가 낮아야 한다.
- 쿼리의 SELECT 절이 인덱스에 포함된 컬럼만으로 구성되어 있어야 한다. (즉, 커버링 인덱스 형태일 때 효과적)
- WHERE 절의 조건은 후행 컬럼 기준으로 탐색해야 한다.
- 실제 데이터 분포가 선두 컬럼 한쪽으로 편향되어 있어야 한다. 즉, Skip Scan은 이론적으로 후행 컬럼만으로 인덱스를 사용할 수 있는 기법이지만, 데이터 분포, 선택도, 카디널리티, 쿼리 형태가 모두 맞아떨어질 때만 실제로 선택된다.
(실제로 아래 예시에서도 전체 행의 대부분이 gender = 'F'이고, gender = 'M'의 비율이 극히 낮은 경우, 옵티마이저는 M에 대한 탐색 비용이 훨씬 낮다고 판단하여 Index Skip Scan 방식을 선택했다.)
🔽 예시 코드
CREATE TABLE employees (
dept_id INT,
gender CHAR(1),
created_at DATETIME,
INDEX idx_created_gender (gender, created_at)
);-- 사용 예시: 선두 컬럼(gender)이 없음에도 인덱스 활용
SELECT gender, created_at FROM employees WHERE created_at = '2025-10-20';🔽 EXPLAIN 결과

▶ Full Table Scan
인덱스를 전혀 사용하지 않고 테이블의 모든 행을 디스크에서 직접 읽는 방식이다.
- 조건절이 인덱스를 활용할 수 없는 경우(%로 시작하는 LIKE, 함수 적용, 데이터 타입 불일치 등), MySQL 옵티마이저는 대부분의 행을 결국 읽어야 한다고 판단할 때 선택한다.
- 모든 행을 순차적으로 읽기 때문에 대용량 테이블에서는 매우 비효율적이다.
- 인덱스 사용이 불가능하거나 비효율적일 때, 옵티마이저가 자동으로 선택하는 마지막 수단이다.
- 시간 복잡도는 O(N)이다.
- N: 전체 행 수
- EXPLAIN
- type: ALL
🔽 예시 코드
CREATE TABLE users (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100)
);-- 사용 예시
SELECT * FROM users;🔽 EXPLAIN 결과

✅ EXPLAIN
EXPLAIN은 MySQL 옵티마이저가 쿼리를 실행하기 전에 테이블에 어떻게 접근하고 데이터를 읽을지를 보여주는 실행 계획 조회 명령어이다.
EXPLAIN SELECT * FROM user WHERE email = 'abc@test.com';이 명령을 실행하면 MySQL이 해당 쿼리를 어떤 방식으로 처리할지를 예측하여 다음 정보를 출력한다.
- 사용되는 인덱스
- 테이블 읽기 순서
- 선택된 조인 방식
- 옵티마이저가 예상하는 처리 행 수
즉, EXPLAIN은 쿼리 실행 전에 실제 수행 계획을 미리 분석하여, 쿼리의 성능을 점검하고 인덱스 활용 여부나 병목 구간을 진단하는 데 사용된다.
🔽 참고
ANALYZE TABLE 명령어는 테이블의 통계 정보를 갱신하는 명령어이다. MySQL 옵티마이저는 이 통계 정보를 기반으로 최적의 실행 계획을 결정하기 때문에, 데이터가 변경된 후 한 번 실행해 주는 것이 좋다. (통계 정보가 자동으로 갱신되는 시점도 존재한다.)
▶ EXPLAIN 주요 컬럼 정리
| 컬럼명 | 설명 |
| id | 쿼리 내 실행 순서(JOIN이나 서브쿼리 등)를 나타내는 식별자 |
| select_type | 쿼리의 유형 (SIMPLE, PRIMARY, UNION, SUBQUERY, DERIVED 등) |
| table | 접근 중인 테이블 이름 |
| partitions | 접근 대상이 되는 파티션 정보 (파티션을 사용하지 않으면 NULL) |
| type | 인덱스 사용 효율을 판단하는 핵심 지표인 접근 방식 |
| possible_keys | 옵티마이저가 사용할 수 있다고 판단한 후보 인덱스 목록 |
| key | 실제로 사용된 인덱스 이름 (인덱스를 사용하지 않으면 NULL) |
| key_len | 인덱스 중 실제로 사용된 길이(byte) (복합 인덱스의 경우 어디까지 사용되었는지 확인 가능) |
| ref | 인덱스를 탐색할 때 사용된 기준값 (컬럼 또는 상수) |
| rows | 옵티마이저가 예측한 읽을 행(row)의 개수 |
| filtered | WHERE 조건을 만족할 것으로 예측되는 행의 비율(%) |
| Extra | 쿼리 실행 시의 추가 정보 (인덱스 사용 방식이나 정렬, 임시 테이블 여부 등) |
이 중에서도 type과 Extra 컬럼은 실행 계획에서 인덱스 사용 여부와 최적화 동작을 확인할 수 있는 핵심 지표이므로, 아래에서 두 컬럼을 중심으로 자세히 살펴보았다.
▶ type 컬럼: 인덱스 접근 방식
EXPLAIN 결과 중 type 컬럼은 얼마나 효율적인 방식으로 데이터를 읽는가를 나타낸다.
🔽 참고
일반적으로 위로 갈수록 성능이 좋아진다.
| type 값 | 스캔 방식 | 설명 |
| system | X | 단 1개의 행만 존재하는 테이블 |
| const | Index Unique Lookup | 조인의 순서와 관계없이 PK나 UNIQUE INDEX의 모든 칼럼에 대해 동등(Equal) 조건으로 검색했을 때 정확히 한 행 조회 |
| eq_ref | Index Unique Lookup (Join) | 조인 시 PK나 UNIQUE KEY의 모든 칼럼에 대해 동등(Equal) 조건으로 검색했을 때 두 번째 테이블에서 정확히 한 행 조회 |
| ref | Index Range Scan | 조인의 순서나 인덱스 종류에 관계 없이 동등(Equal) 조건으로 검색 |
| ref_or_null | Index Range Scan + NULL 탐색 | ref 혹은 IS NULL 조건을 검색 |
| range | Index Range Scan | BETWEEN, <, >, IN, LIKE 'abc%' 같은 범위 조건으로 검색 |
| index_merge | Index Merge Scan | 여러 인덱스를 동시에 사용하여 Union/Intersection 수행 |
| unique_subquery | Index Lookup (Subquery) | 서브 쿼리에서 중복되지 않는 유니크한 값 조회 |
| index_subquery | Index Range Scan (Subquery) | 서브 쿼리에서 중복된 값 조회 |
| fulltext | Fulltext Scan | MATCH ... AGAINST 기반의 전문 검색 |
| index | Index Full Scan | 인덱스 전체를 순차적으로 검색 (Using index 있으면 커버링 인덱스) |
| ALL | Full Table Scan | 인덱스 사용하지 않고 테이블 전체를 읽음 |
🔽 system
CREATE TABLE one_row (
col INT
) ENGINE=MEMORY;
INSERT INTO one_row SELECT 1;
EXPLAIN SELECT * FROM one_row;
- 단 1개의 행만 존재하는 테이블로, 상수 역할을 하는 정적 값을 저장할 때 사용된다.
- InnoDB 엔진에서는 나타나지 않으며, MEMORY나 MyISAM과 같은 엔진에서만 확인할 수 있다.
🔽 const
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50)
);
EXPLAIN SELECT * FROM users WHERE id = 1;
- PRIMARY KEY 또는 UNIQUE KEY 컬럼에 대해 정확히 일치하는 값을 검색할 때 사용된다.
- 조회 결과가 하나의 행으로 확정되므로, 옵티마이저는 이를 상수(constant)처럼 취급한다.
🔽 eq_ref
CREATE TABLE departments (
id INT PRIMARY KEY,
name VARCHAR(50)
);
CREATE TABLE employees (
id INT PRIMARY KEY,
dept_id INT,
FOREIGN KEY (dept_id) REFERENCES departments(id)
);
EXPLAIN SELECT e.id, d.name FROM employees e JOIN departments d ON e.dept_id = d.id;
- 조인 시, PRIMARY KEY 또는 UNIQUE KEY를 기준으로 1:1 매칭이 이루어지는 경우에 사용된다.
- 각 employees 행의 dept_id는 departments.id의 정확히 하나의 행과 매칭된다.
🔽 ref
CREATE TABLE posts (
id INT PRIMARY KEY,
author_id INT,
INDEX idx_author (author_id)
);
EXPLAIN SELECT * FROM posts WHERE author_id = 5;
- 인덱스의 일부 컬럼에 대해 동등(=) 조건으로 검색할 때 사용된다.
- 하나의 키 값이 여러 행을 참조할 수 있는 1:N 관계에서 주로 발생한다.
- idx_author를 통해 여러 행이 매칭될 수 있다.
🔽 ref_or_null
CREATE TABLE comments (
id INT PRIMARY KEY,
parent_id INT,
INDEX idx_parent (parent_id)
);
EXPLAIN SELECT * FROM comments WHERE parent_id = 10 OR parent_id IS NULL;
- = 조건과 IS NULL 조건을 함께 사용하는 경우에 나타난다.
- idx_parent를 이용해 parent_id = 10인 행과 parent_id IS NULL인 행을 모두 검색한다.
🔽 range
CREATE TABLE orders (
id INT PRIMARY KEY,
price INT,
INDEX idx_price (price)
);
EXPLAIN SELECT * FROM orders WHERE price BETWEEN 100 AND 500;
- 인덱스의 범위 조건(BETWEEN, <, >, <=, >=)으로 검색하는 경우이다.
- 옵티마이저는 인덱스의 연속된 구간(range) 만 스캔하며, 조건에 맞는 레코드만 읽는다.
🔽 index_merge
CREATE TABLE products (
id INT PRIMARY KEY,
category VARCHAR(50),
brand VARCHAR(50),
INDEX idx_category (category),
INDEX idx_brand (brand)
);
EXPLAIN SELECT * FROM products WHERE category = 'food' OR brand = 'nike';

- 두 개 이상의 인덱스를 결합(병합)하여 검색하는 방식이다.
- 옵티마이저가 각 인덱스의 검색 결과를 합쳐(또는 교집합으로 묶어) 최종 결과를 반환하며, Using union 또는 Using intersect 형태로 표시될 수 있다.
- idx_category와 idx_brand 인덱스를 UNION 형태로 병합해 조건(OR)을 만족하는 행을 찾는다.
🔽 unique_subquery
CREATE TABLE cities (
id INT PRIMARY KEY,
name VARCHAR(50) UNIQUE
);
CREATE TABLE users_city (
id INT PRIMARY KEY,
city_id INT,
FOREIGN KEY (city_id) REFERENCES cities(id)
);
EXPLAIN SELECT * FROM users_city WHERE city_id = (SELECT id FROM cities WHERE name = 'Seoul');
- 서브쿼리의 결과가 단 하나의 고유(UNIQUE) 값으로 반환될 때 사용된다.
- 내부적으로 PRIMARY KEY 또는 UNIQUE KEY를 이용해 정확히 한 행만 매칭된다.
🔽 참고
최신 MySQL(InnoDB) 버전에서는 옵티마이저가 쿼리를 자동으로 리라이트(Rewrite)하여 최적화하기 때문에, 실제 실행 계획에서 unique_subquery 타입을 찾기 어려웠다.
🔽 index_subquery
CREATE TABLE orders_sub (
id INT PRIMARY KEY,
customer_id INT,
INDEX idx_customer (customer_id)
);
SET optimizer_switch='subquery_to_derived=off';
SET optimizer_switch='semijoin=off';
EXPLAIN SELECT * FROM orders_sub WHERE customer_id IN (SELECT customer_id FROM orders_sub WHERE id < 10);
- 서브쿼리에서 중복 가능한 값을 반환하는 경우에 사용된다.
- unique_subquery와 달리, 반환되는 키 값이 고유하지 않아 여러 번 참조될 가능성이 있다.
- 서브쿼리의 결과가 인덱스(idx_customer)를 활용해 여러 행과 매칭될 수 있으며, 중복된 키를 포함한 IN 조건으로 처리된다.
🔽 참고
MySQL 8.0에서는 기본적으로 서브쿼리를 세미조인(Semi-Join) 또는 파생 테이블(Derived Table)로 최적화하기 때문에 실제로 index_subquery 타입을 확인하려면 다음과 같이 옵티마이저 최적화를 비활성화해야 한다.
- SET optimizer_switch='subquery_to_derived=off';
- SET optimizer_switch='semijoin=off';
🔽 fulltext
CREATE TABLE articles (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255),
content TEXT,
FULLTEXT INDEX idx_fulltext (title, content)
);
EXPLAIN SELECT * FROM articles WHERE MATCH(title, content) AGAINST ('database' IN NATURAL LANGUAGE MODE);
- 전문 검색(Full-Text Search)을 위해 사용되는 인덱스이다.
🔽 index
CREATE TABLE products_index (
id INT PRIMARY KEY,
name VARCHAR(50),
INDEX idx_name (name)
);
EXPLAIN SELECT name FROM products_index;
- 인덱스의 리프 노드만 순차적으로 스캔하는 방식이다.
- 조회 대상 컬럼(name)이 인덱스에 모두 포함되어 있어 실제 테이블(데이터 영역)에 접근하지 않는다. 즉, 커버링 인덱스(covering index) 형태로 작동한다.
🔽 ALL
CREATE TABLE users_all (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT
);
EXPLAIN SELECT * FROM users_all WHERE age = 30;
- 테이블의 모든 행을 순차적으로 읽는 Full Table Scan으로, 가장 비효율적인 방식이다.
▶ Extra 컬럼: 인덱스 관련 주요 정보
| Extra 값 | 의미 | 설명 |
| Using index | 커버링 인덱스 사용 | 인덱스만으로 필요한 컬럼을 모두 조회, 실제 테이블 접근 안 함 |
| Using where | WHERE 조건 필터링 | 인덱스를 일부만 사용했거나 조건이 인덱스 외 컬럼 포함 |
| Using temporary | 임시 테이블 사용 | GROUP BY, DISTINCT 등으로 메모리 임시 테이블 생성 |
| Using filesort | 추가 정렬 발생 | 인덱스로 정렬되지 않아 별도 정렬 수행 (ORDER BY 문제) |
| Using index condition | ICP(Index Condition Pushdown) | 인덱스 리프 스캔 중 WHERE 조건을 푸시다운해 필터링 (InnoDB 최적화) |
🔽 Using index
CREATE TABLE employees (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
department_id INT,
INDEX idx_department (department_id)
);
EXPLAIN SELECT department_id FROM employees WHERE department_id = 3;
- 조회 대상 컬럼이 인덱스에 모두 포함되어 있어 실제 테이블(데이터 영역)에 접근하지 않는다. 즉, 커버링 인덱스(covering index) 형태로 작동한다.
🔽 Using where
CREATE TABLE employees (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
department_id INT,
INDEX idx_department (department_id)
);
EXPLAIN SELECT * FROM employees WHERE department_id = 3 AND name = 'Alice';

- department_id = 3은 인덱스로 찾지만, name = 'Alice'는 인덱스에 없어 실제 데이터에서 추가 필터링이 수행된다.
🔽 Using temporary
CREATE TABLE employees (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
department_id INT,
INDEX idx_department (department_id)
);
EXPLAIN SELECT DISTINCT name FROM employees;
- DISTINCT 연산을 수행하기 위해 내부적으로 임시 테이블을 생성한다.
🔽 Using filesort
CREATE TABLE employees (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
department_id INT,
INDEX idx_department (department_id)
);
EXPLAIN SELECT * FROM employees ORDER BY name;
- name 컬럼에 인덱스가 없어 인덱스 순서로 정렬할 수 없으므로, MySQL이 모든 행을 읽은 뒤 메모리나 디스크에서 별도로 정렬(filesort)한다.
🔽 Using index condition
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
customer_id INT,
total_amount INT,
status VARCHAR(10),
INDEX idx_customer_amount (customer_id, total_amount)
);
EXPLAIN SELECT status FROM orders WHERE customer_id > 10 AND total_amount > 5000;

- 선두 컬럼 customer_id로 인덱스 범위를 스캔하면서, 후행 컬럼 total_amount 조건을 인덱스 리프 단계에서 푸시다운해 불필요한 데이터 접근을 줄이므로 ICP(Index Condition Pushdown)가 발생한다.
🔽 참고
ICP(Index Condition Pushdown): 인덱스 리프 노드에서 WHERE 조건 일부를 미리 평가하여, 불필요한 데이터 페이지 접근을 줄이는 방식
✅ 인덱스를 비효율적으로 사용하는 경우
🔽 참고
최근 MySQL 옵티마이저는 내부 최적화 수준이 크게 향상되어, 과거에는 Full Table Scan으로 처리되던 쿼리도 상황에 따라 Index Full Scan 등으로 자동 변환하여 더 효율적인 방식으로 실행한다. 그러나 진정한 의미의 인덱스 활용은 단순히 옵티마이저의 자동 최적화에 의존하는 것이 아니라 InnoDB의 데이터 저장 구조를 이해하고 그에 맞게 인덱스를 설계 및 활용하는 것에서 비롯되기 때문에, 다음과 같은 케이스들을 잘 숙지하는 것이 중요하다고 생각한다.
▶ WHERE 절에서 함수 사용
🔽 예시 코드
WHERE DATE(created_at) = '2025-01-01'인덱스는 컬럼의 원본 값을 기준으로 정렬되어 있다. 하지만 DATE(created_at)처럼 컬럼에 함수를 적용하면, MySQL은 인덱스의 정렬 순서를 활용할 수 없어 모든 행을 읽은 뒤 함수를 적용하여 비교해야 한다.
🔽 해결 방법
WHERE created_at >= '2025-01-01' AND created_at < '2025-01-02'함수 적용을 피하고, 범위 조건으로 변환하여 인덱스를 활용한다.
▶ 부정 조건
🔽 예시 코드
WHERE age != 30;
WHERE name NOT LIKE 'A%';
WHERE id NOT IN (1, 2, 3);인덱스는 특정 값이나 범위를 빠르게 찾는 구조이지만, 부정 조건은 그 값을 제외한 나머지 전부를 의미한다. 즉, 인덱스를 사용하더라도 탐색 범위가 너무 넓어 효율이 떨어진다.
🔽 해결 방법
WHERE age BETWEEN 0 AND 29 OR age BETWEEN 31 AND 100;부정 조건을 긍정 조건의 범위 검색으로 재작성하여 인덱스 사용이 가능하도록 한다.
▶ 앞에 와일드카드(%) 사용
🔽 예시 코드
WHERE name LIKE '%abc'B-Tree 인덱스는 문자열의 왼쪽부터 정렬되어 저장된다. '%abc'처럼 앞부분이 불확정한 경우 인덱스의 탐색 경로를 계산할 수 없다.
🔽 해결 방법
LIKE 'abc%'접두사를 고정하여 인덱스 탐색이 가능한 방식을 사용한다.
▶ 데이터 형변환 (암묵적 캐스팅)
🔽 예시 코드
WHERE number = '123'MySQL은 비교 시 양쪽의 타입을 일치시키기 위해 암묵적 형변환을 수행한다. 이때 인덱스 컬럼이 문자열로 변환되면 인덱스의 정렬 구조가 깨진다.
🔽 해결 방법
WHERE number = 123양쪽의 데이터 타입을 일치시켜 인덱스를 활용한다.
▶ OR 조건 (단일 컬럼 인덱스)
🔽 예시 코드
WHERE a = 1 OR b = 2a 컬럼에만 인덱스가 존재하고 b에는 인덱스가 없을 경우, MySQL은 a = 1 조건에 대해서만 인덱스를 사용할 수 있다. b = 2 조건은 인덱스를 사용할 수 없어 테이블 전체를 스캔해야 하며, 결과적으로 옵티마이저는 비용이 더 낮은 Full Table Scan을 선택할 가능성이 높다.
🔽 해결 방법
SELECT * FROM t WHERE a = 1
UNION ALL
SELECT * FROM t WHERE b = 2;a 조건에서는 인덱스를 활용하고, b 조건은 별도로 조회하여 UNION ALL로 병합하면 성능을 개선할 수 있다.
📍 참고 자료
- MySQL 공식 문서 - 10.3.1 How MySQL Uses Indexes
- MySQL 공식 문서 - 15.1.15 CREATE INDEX Statement
- MySQL 공식 문서 - 10.8.2 EXPLAIN Output Format
- MySQL 공식 문서 - 15.8.2 EXPLAIN Statement
- Real MySQL 8.0 - 8. 인덱스
- Real MySQL 8.0 - 10. 실행 계획
- MySQL에서 Index가 사용되지 않는 대표적인 5가지 경우와 이유 알아보기
'Backend > Database' 카테고리의 다른 글
| [Database] 복합 인덱스에서 컬럼 순서는 어떻게 결정해야 할까 (1) | 2025.12.30 |
|---|---|
| [Database] 인덱스(Index) (1) (0) | 2025.10.14 |
| [Database] MySQL(InnoDB) 락(Lock) (2) (2) | 2025.10.06 |
| [Database] 락(Lock) (1) (0) | 2025.10.04 |
| [Database] 동시성 문제(Read 계열), 트랜잭션 격리 수준 (1) | 2025.10.01 |