
우아한테크코스 레벨 4 팀 프로젝트 festabook에서 학습한 내용을 정리한 글입니다.
💭 들어가며
TPS라는 용어는 익숙하게 들어왔지만, 막상 직접 측정해 보니 혼란스러운 부분이 많았다. 인터넷을 찾아보면 TPS를 어떻게 측정하는지에 대한 글은 많지만, 왜 측정해야 하는지를 명확히 설명한 글은 드물었다.
우리 팀 역시 처음에는 미션 수행을 위해 단순히 “서버의 TPS를 얼마나 끌어올릴 수 있을까?”라는 호기심에서 출발했다. 그러나 여러 번의 실험과 시도를 거치며 TPS가 단순한 수치 경쟁의 대상이 아니라, 시스템의 처리 한계를 진단하고 병목 구간을 파악하기 위한 핵심 지표임을 깨달았다.
이 글은 나처럼 TPS와 RPS가 낯설고 감이 잘 잡히지 않는 사람들을 위해 작성했다. 단순히 측정 방법을 다루기보다는, 실제 TPS 측정 경험을 기반으로 왜 TPS를 측정해야 하는지, 그리고 어떤 상황에서 어떤 의미로 활용되는지를 정리했다.
✅ TPS, RPS
▶ TPS(Transactions Per Second)
TPS는 서버가 1초 동안 처리한 트랜잭션의 개수를 의미한다. 여기서 트랜잭션(Transaction)이란 논리적으로 완결된 하나의 작업 단위를 말한다. 즉, 데이터베이스에서 하나 이상의 SQL 연산(SELECT, INSERT, UPDATE, DELETE 등)을 포함하여 하나의 비즈니스 로직을 완성하는 과정을 의미한다.
예를 들어, 주문 생성은 상품 조회, 재고 감소, 결제 정보 저장, 영수증 생성 등 여러 단계를 거치는데, 이 전체 과정을 하나의 트랜잭션으로 본다. 따라서 TPS는 이러한 비즈니스 로직 단위의 초당 처리량을 나타내는 지표다.
- 주로 DB 또는 WAS 성능 측정에 사용된다.
- 트랜잭션은 내부적으로 여러 개의 HTTP 요청이나 SQL 쿼리를 포함할 수 있다.
- JMeter, k6 등의 테스트 도구에서는 일반적으로 “성공한 트랜잭션 수 ÷ 초”로 계산한다.
▶ RPS(Requests Per Second)
RPS는 서버가 1초 동안 처리한 HTTP 요청(Request)의 개수를 의미한다. 트랜잭션보다 더 세분화된 단위로, 단순히 요청이 들어와 응답이 완료된 횟수를 센다.
예를 들어, /api/products(상품 조회), /api/orders(주문 생성), /api/payments(결제 확인) 세 개의 API가 각각 초당 10번씩 호출된다면, RPS는 30이 된다. 즉, RPS는 요청과 응답 단위의 처리량을 의미한다.
- 주로 웹 서버, API 게이트웨이, 로드밸런서 수준의 처리 성능을 평가할 때 사용된다.
- 하나의 트랜잭션이 여러 개의 요청으로 구성될 수 있으므로, 일반적으로 RPS ≥ TPS 관계가 성립한다.
✅ TPS와 RPS 지표가 필요한 경우
결론부터 말하자면, TPS와 RPS는 단순히 숫자를 높이기 위한 경쟁 지표가 아니라, 시스템의 한계를 검증하고 안정적인 운영을 보장하기 위한 핵심 성능 지표다.
처음에는 단순히 TPS와 RPS를 높여보고자 여러 가지 실험을 해봤지만, 결국 지표를 올리는 것 자체에는 큰 의미가 없다는 걸 깨달았다. 단순히 서버 사양을 Scale Up하면 TPS는 자연히 상승하기 때문이다. 중요한 것은 “왜” 이 지표를 측정하고 “무엇을” 개선하기 위함인가다. 그 목적을 명확히 하면, TPS와 RPS는 훨씬 가치 있는 지표가 된다.
이 지표는 크게 두 가지 상황에서 활용된다.
- 서버 설정을 튜닝하기 위한 경우
- 동시 접속자를 고려해야 하는 기능을 검증하기 위한 경우
▶ 서버 설정 튜닝을 위한 기준
서버 설정은 단순히 x, y처럼 몇 가지 값을 조정한다고 해결되는 문제가 아니다. CPU 코어 수, 커넥션 풀 크기, 스레드 풀 설정, 네트워크 지연, GC 정책 등 수많은 변수가 서로 영향을 주고받으며 작동한다. 이러한 복잡한 환경 속에서 특정 설정이 실제로 서버 성능을 개선했는지를 판단하기 위해서는 객관적이고 일관된 지표가 필요하다. 그 지표가 바로 TPS와 RPS다.
예를 들어, HikariCP의 maximumPoolSize나 Tomcat의 max-threads, accept-count 같은 설정을 변경할 때, 이전과 동일한 조건에서 부하 테스트를 반복 수행해야 한다. (테스트 환경을 통제(변인 통제)한 뒤, 설정을 변경하고 부하 테스트를 반복 수행하며, TPS/RPS 변화를 비교하여 성능 개선 여부 판단)
이렇게 하나의 설정만 변경한 뒤 동일한 조건에서 테스트를 반복 수행하고, 각 실험에서 측정된 TPS와 RPS의 변화를 비교함으로써 해당 설정이 성능 향상에 긍정적인 영향을 주었는지를 판단할 수 있다. 결국 TPS와 RPS는 단순한 성능 지표가 아니라, 서버 설정이 성능 향상에 실질적으로 기여했는지를 검증하는 기준선 역할을 한다.
▶ 동시 트래픽 대응을 위한 기준
또 다른 활용 목적은 동시 접속자를 고려해야 하는 기능을 설계하거나 검증할 때다.
예를 들어, 우리 서비스는 연예인 라인업을 특정 시점에 예약 공개하는 기능, 선착순 줄서기 기능, 학생회가 전 학생에게 공지 푸시 알림을 발송하는 기능 등이 있었다.
이러한 기능은 모두 짧은 시간에 대량의 요청이 몰리는 순간적 트래픽 피크가 발생한다. 이때 서버가 감당할 수 있는 요청의 한계치를 미리 파악하지 않으면, 예기치 못한 서버 다운이나 장애로 이어질 수 있다.
따라서 TPS와 RPS를 활용해 “우리 서버가 초당 몇 건의 트랜잭션 또는 요청을 안정적으로 처리할 수 있는가”를 사전에 측정하고, 이 수치를 바탕으로 트래픽 대응 전략(스케일링, 큐잉, 캐싱, 메시지 브로커 등)을 수립하는 것이 중요하다.
✅ 서버 설정 튜닝
서버 설정 튜닝은 서버의 하드웨어 사양이 변경될 때 함께 조정되어야 하는 항목이기 때문에, 환경 변화에도 대응할 수 있도록 범용성 있는 기준값으로 설정하려 노력했다. 이를 위해 공식 문서에서 권장하는 지표를 참고하여 합리적인 수치로 조정하였다.
▶ HikariCP 설정
spring:
datasource:
hikari:
maximum-pool-size: 10 # 최대 풀 크기1️⃣ HikariCP 최대 풀 크기(maximum-pool-size) 설정
- 이전에 작성한 HikariCP 설정 관련 블로그에서 언급했듯, DB CPU 코어 수를 기준으로 풀 크기를 산정했다. 해당 DB 인스턴스는 2코어 환경이었으며, 공식 문서에서 제시하는 connections = ((core_count * 2) + effective_spindle_count) 공식을 기반으로 초기값을 도출했다. 이후 네트워크 RTT, InnoDB 락 대기, fsync, 스토리지 지연 등 다양한 병목 지점을 고려해 풀 크기를 점진적으로 확장하며 부하 테스트를 수행했다. 변인을 통제한 실험 결과, 기본 설정값인 10에서 TPS 및 지연 시간의 균형이 가장 안정적으로 나타났다.
- 또한, Deadlock 회피를 위한 커넥션 풀 공식 pool size ≥ Tn × (Cm - 1) + 1 (Tn: 트랜잭션 수, Cm: 동시 처리 커넥션 수)에서도 10 ≥ 15 × (1 - 1) + 1 조건을 만족했다.
→ 따라서, HikariCP의 최대 풀 크기를 10으로 설정했다.
▶ Tomcat 설정
server:
tomcat:
threads:
max: 15 # 요청을 처리할 최대 스레드 수
# accept-count: 100 # 대기 중인 연결 요청 큐의 크기 (기본값)
# max-connections: 10000 # 동시에 유지할 수 있는 최대 TCP 연결 수 (기본값)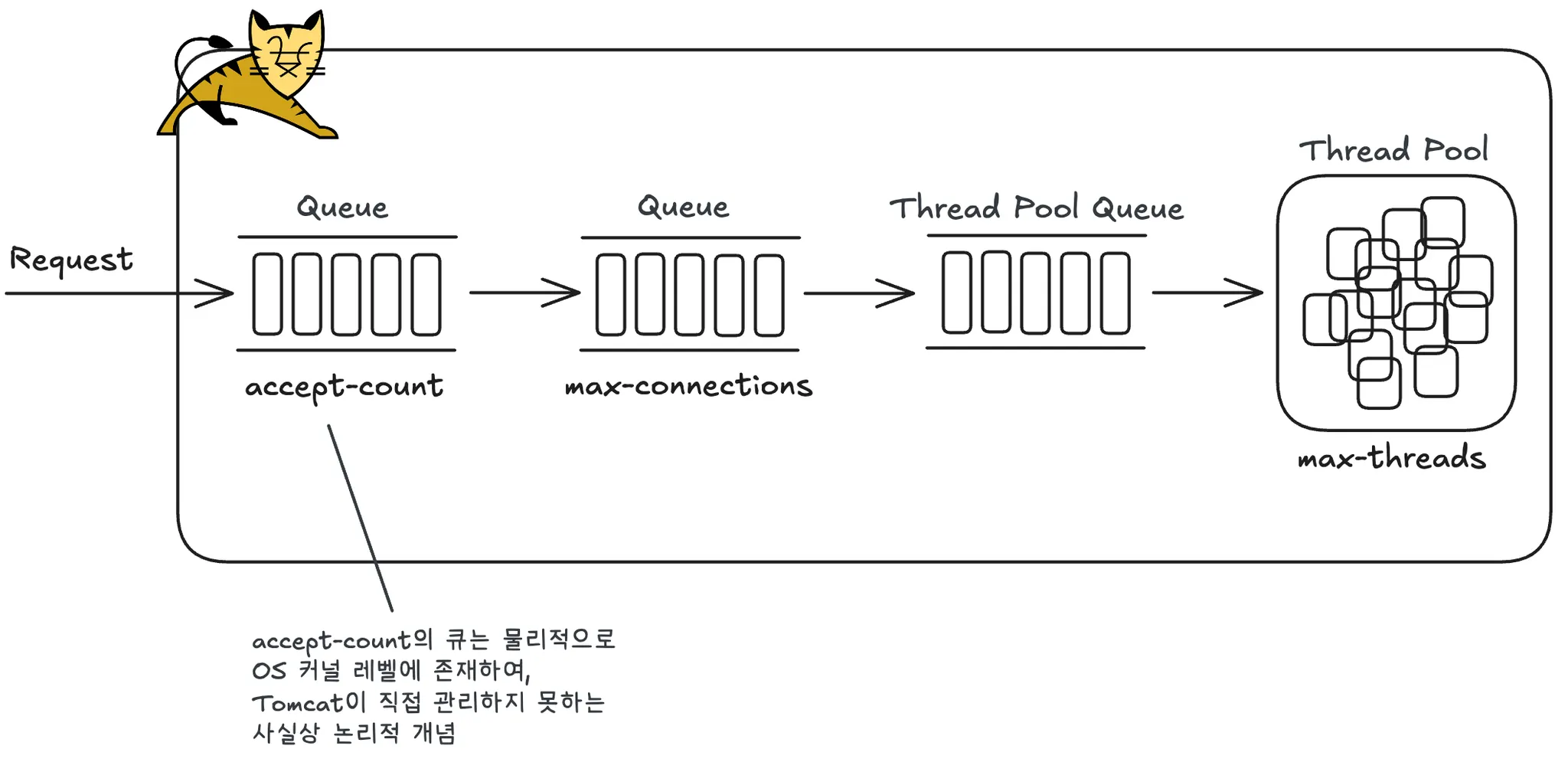
1️⃣ 최대 스레드 수(max-threads) 설정
- 최대 스레드 수는 앞서 설정한 커넥션 풀 크기를 기준으로, 이보다 약간 큰 범위에서 10~200 사이의 값을 단계적으로 조정하며 TPS를 측정했다. 그 결과, 스레드 15개일 때 TPS와 응답 지연 시간 간의 균형이 가장 안정적으로 유지되는 것을 확인했다.
→ 따라서, 최대 스레드 수를 15로 설정했다.
2️⃣ 대기 중인 연결 요청 큐 크기(accept-count) 설정

- 사실 accept-count는 OS 커널 레벨의 TCP backlog 큐 크기를 설정하는 파라미터로, Tomcat이 직접 제어하기보다는 운영체제 설정에 영향을 받는다. Tomcat 공식 문서에 따르면, accept-count 값을 설정하더라도 운영체제에 따라 이 설정이 무시될 수 있다.
- 초기에는 메모리 사용량을 줄이기 위해 max-connections를 축소하고 accept-count를 확대하는 방안을 검토했다. 그러나 이는 OS가 큐를 자체적으로 처리할 가능성이 높아 예상과 다르게 동작할 수 있으며, 사용자 수가 많아질 경우 요청을 느리게라도 처리하지 못하고, request refused가 발생할 위험이 있었다.
→ 따라서, 연결 요청 큐 크기는 기본값(100)을 유지했다.
3️⃣ 최대 연결 수(max-connections) 설정
- 앞서 살펴본 것처럼, max-connections를 줄이고 accept-count를 늘리는 방식으로 리소스 절감을 검토했지만, 이 경우 요청이 느리더라도 정상 응답으로 처리될 수 있는 상황에서도 request refused가 발생할 위험이 있었다.
→ 따라서, 최대 연결 수도 기본값(10,000)을 유지했다.
Thread Pool Queue의 크기는 Integer.MAX_VALUE로 선언되어 있으며, Tomcat 내부에서 직접 수정할 수 없다.
▶ JDBC 드라이버 설정 (MySQL)
spring:
datasource:
hikari:
data-source-properties:
cachePrepStmts: true
prepStmtCacheSize: 250
prepStmtCacheSqlLimit: 2048
useServerPrepStmts: true
useLocalSessionState: true
rewriteBatchedStatements: true
cacheResultSetMetadata: true
cacheServerConfiguration: true
elideSetAutoCommits: true
maintainTimeStats: false위 설정은 HikariCP 공식 문서에서 제시하는 MySQL 최적화 권장 설정이다. 문서에 따르면, MySQL 환경에서 HikariCP의 성능을 극대화하기 위해 위 옵션들을 적용하는 것이 바람직하며, 각 설정의 세부 동작 원리와 효과를 이해하기 위해 공식 문서 전문을 직접 읽어보는 것을 권장한다.
▶ MySQL 설정
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
innodb_buffer_pool_size = 1536M # InnoDB 버퍼풀
innodb_buffer_pool_instances = 2 # InnoDB 버퍼풀 인스턴스
max_connections = 80 # 최대 연결 수1️⃣ InnoDB 버퍼 풀 사이즈(innodb_buffer_pool_size) 설정

- 디스크 접근보다 메모리 접근 속도가 훨씬 빠르기 때문에, 가능한 많은 데이터를 메모리에 적재하도록 설정하고 싶었고, MySQL 공식 문서에서는 전체 RAM의 50~75% 수준으로 InnoDB 버퍼 풀 크기를 설정하도록 권장한다.
- InnoDB 버퍼 풀 외에도 Undo Log Buffer 등 다른 구성 요소도 메모리를 사용하므로 여유를 두어야 한다.
- 이에 따라 전체 메모리의 약 70%인 1.4GB(=1400M)로 설정했으나, 실제 MySQL이 내부적으로 버퍼 풀 크기를 innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances의 배수로 자동 조정하기 때문에, 설정값이 자동으로 1536M(=1610612736 bytes)으로 변경되었다.
→ 따라서, InnoDB 버퍼 풀 사이즈를 명시적으로 1536M로 설정했다.
2️⃣ InnoDB 버퍼 풀 인스턴스(innodb_buffer_pool_instances) 설정

- MySQL 공식 문서에 따르면, 1GB 이상의 버퍼 풀 크기당 하나의 인스턴스로 설정하면 동시성을 향상시킬 수 있다. 각 인스턴스는 독립적으로 관리되어 락 경합을 줄인다.
- 우리 서버의 총 메모리는 1536M로 제한했으므로, 권장 기준에 따라 1개의 인스턴스를 사용하는 것이 가장 효율적이다. 다만, 전체 버퍼 풀을 768MB씩 나누어 2개의 인스턴스로 구성하더라도 성능 차이는 크지 않을 것으로 판단했으며, 추후 서버 메모리 확장(Scale-Up)을 고려해 미리 다중 인스턴스 구성을 적용했다.
→ 따라서, InnoDB 버퍼 풀 인스턴스 수를 2로 설정했다.
3️⃣ 최대 연결 수(max_connections) 설정
- max_connections은 단순한 설정값이 아니라 MySQL 서버가 동시에 수용할 연결 수만큼의 메모리를 미리 확보해야 하는 설정이다. 즉, 너무 높게 설정하면 연결당 스레드 스택과 세션 버퍼로 인해 불필요한 메모리 점유가 발생할 수 있다.
- 현재 애플리케이션 서버는 컨테이너 1개당 최대 10개의 커넥션을 사용하며, 오토스케일링 3개 인스턴스, Blue-Green 배포 시 동시 6개 인스턴스 존재 가능성을 고려하였다.
- 또한, Grafana 등 서드파티 모니터링 도구가 DB 커넥션을 점유할 수 있으므로, 약간의 여유를 두었다.
→ 따라서, 최대 연결 수를 80으로 설정했다.
▶ JVM 설정
# java -XX:+UseG1GC -jar app.jar # GC 알고리즘 (기본값)
# java -Xms{최소값}m -Xmx{최대값}m -jar app.jar # JVM 메모리 제한 (기본값)1️⃣ GC 알고리즘 변경
- Java 9부터 G1GC(Garbage First Garbage Collector)가 JVM의 기본 가비지 컬렉터로 사용되고 있다. John Grib님의 Java GC 튜닝 글에 따르면, 서비스의 특성에 따라 GC는 처리량(Throughput) 중심과 응답 시간(Latency) 중심으로 나뉘는데, 우리 서비스는 여느 현대적인 웹 애플리케이션과 마찬가지로 응답 시간(지연 시간)이 처리율보다 중요한 구조다. 또한, GC 일시 정지(Stop-The-World) 시간이 짧을수록 사용자 경험이 개선되기 때문에, 기본으로 채택된 G1GC가 서비스 특성과 잘 맞는다고 판단했다.
→ 따라서, GC 알고리즘은 기본값(G1GC)을 유지했다.
2️⃣ JVM 메모리 제한 설정

- OpenJDK 공식 문서에 따르면 JVM은 -Xms(초기 힙 크기)와 -Xmx(최대 힙 크기)를 별도로 지정하지 않으면, 운영체제의 가용 물리 메모리(RAM) 용량을 기준으로 자동으로 힙 크기를 산정한다.
- 현재 JVM 메트릭을 확인한 결과, GC가 안정적으로 동작하고 있으며 메모리 사용량도 위험 구간의 절반에도 도달하지 않았다. 즉, 자동 힙 사이징으로도 애플리케이션이 충분히 안정적으로 운영되고 있음을 확인했다.
- 이에 따라 현재 설정을 유지하되, 추후 Scale Down 또는 Scale Out 시점에서 메모리 제한 설정을 재검토하기로 결정했다.
→ 따라서, JVM 메모리 제한은 기본값을 유지했다.
▶ 결과
🔽 서버 튜닝 전

🔽 서버 튜닝 후

서버 튜닝 이후 TPS가 약 22.9% 상승한 것을 확인할 수 있었다.
🔽 스크립트
sudo ./k6.sh 300 300 결과보고서🔽 k6 스크립트
#!/bin/bash
# k6.sh
# 매개변수 검사
if [ "$#" -lt 3 ]; then
echo "매개변수가 부족합니다."
echo "사용법: $0 <예열_VUS> <측정_VUS> <결과파일이름>"
exit 1
fi
# 변수 설정
WARMUP_VUS=${1}
TEST_VUS=${2}
RESULT_FILE_NAME=${3}
RESULT_PATH="/var/www/html/${RESULT_FILE_NAME}.html"
WARM_WAIT_TIME=10
# 서버 예열 시작
echo "--- 1. 서버 예열 시작 ---"
sudo k6 run -e VUS_COUNT=${WARMUP_VUS} warm.js
if [ $? -eq 0 ]; then
echo "예열이 완료되었습니다. 서버 안정화를 위해 $WARM_WAIT_TIME 초를 대기합니다."
sleep $WARM_WAIT_TIME
else
echo "예열 스크립트 실행 중 오류가 발생했습니다."
exit 1
fi
# 성능 측정 시작
echo "--- 2. 성능 측정 시작 ---"
sudo k6 run -e VUS_COUNT=${TEST_VUS} --out dashboard=export=${RESULT_PATH} main.js
if [ $? -eq 0 ]; then
echo "성능 측정이 완료되었습니다. 결과는 ${RESULT_PATH} 경로에서 확인할 수 있습니다."
else
echo "성능 측정 실행 중 오류가 발생했습니다."
fi🔽 warm.js 스크립트
import http from "k6/http";
import { check, sleep } from "k6";
import { Counter } from "k6/metrics";
const VUS = parseInt(__ENV.VUS_COUNT || "300");
const successCount = new Counter("success_count");
const failCount = new Counter("fail_count");
export const options = {
scenarios: {
load_test: {
executor: "constant-vus", // 지속적인 VU를 유지하는 실행기
vus: VUS,
duration: "300s",
gracefulStop: "0s", // 테스트가 종료 시점에 즉시 중단
},
},
};
export default function () {
const url = "{엔드포인트}";
const params = {
headers: { // 헤더 추가
"Content-Type": "application/json"
},
};
const res = http.get(url, params);
// check로 상태 확인
const ok = check(res, {
"status is 200": (r) => r.status === 200,
});
// check 결과 기반으로 counter 증가
if (ok) {
successCount.add(1);
} else {
failCount.add(1);
}
sleep(0);
}🔽 main.js 스크립트
import { check, sleep } from "k6";
import { Counter } from "k6/metrics";
const VUS = parseInt(__ENV.VUS_COUNT || "300");
const successCount = new Counter("success_count");
const failCount = new Counter("fail_count");
export const options = {
scenarios: {
load_test: {
executor: "constant-vus", // 지속적인 VU를 유지하는 실행기
vus: VUS,
duration: "60s",
gracefulStop: "0s", // 테스트가 종료 시점에 즉시 중단
},
},
};
export default function () {
const url = "{엔드포인트}";
const params = {
headers: { // 헤더 추가
"Content-Type": "application/json"
},
};
const res = http.get(url, params);
// check로 상태 확인
const ok = check(res, {
"status is 200": (r) => r.status === 200,
});
// check 결과 기반으로 counter 증가
if (ok) {
successCount.add(1);
} else {
failCount.add(1);
}
sleep(0);
}시각화는 xk6-dashboard 플러그인을 통해 구현했다. Go 언어, xk6 빌드 도구, 그리고 xk6-dashboard를 포함해 k6를 빌드하면 테스트 결과를 실시간 대시보드 또는 HTML 리포트 형태로 시각화할 수 있다. Apache 웹 서버를 설치해 /var/www/html 경로를 노출하면 http://서버_IP/ 접속 시 테스트 결과 리포트를 바로 확인할 수 있다. k6 스크립트에서는 HTML 결과 파일이 자동으로 /var/www/html에 저장되도록 설정했기 때문에 테스트 완료 후 별도 복사 없이 바로 브라우저에서 대시보드를 열람할 수 있다.
본문에서는 부하 테스트 환경 구성 절차가 길어져 제외했으며, 동일한 환경을 직접 재현하고 싶다면 생성형 AI에게 요청하면 상세히 안내받을 수 있다.
✅ 동시 트래픽 대응
동시 접속자를 고려해야 하는 기능을 검증할 때 TPS를 어떻게 활용해야 할지 고민이 많았다. 이는 서비스의 목적과 트래픽 패턴에 따라 TPS를 해석하고 사용하는 방식이 달라지기 때문에 명확한 정답이 존재하지 않는다.
우리 서비스에서도 동시 접속자를 고려해야 하는 기능이 있었고, 이를 기반으로 실제 테스트를 수행하며 TPS를 어떻게 활용했는지를 정리했다.
▶ 동시 트래픽 대응 검증에서 TPS 활용 방법
1️⃣ 특정 트랜잭션의 한계 TPS 찾기 (기준점 설정)

위 그래프는 TPS의 이론적 변화 곡선이다. 테스트는 트랜잭션 단위(특정 엔드포인트 묶음)로 수행되며, 300명 → 500명 → 1000명 → 1500명 → 3000명 → 5000명처럼 동시 사용자 수를 점진적으로 늘려가며 TPS가 수렴하는 구간을 찾는다.
이 수렴점은 해당 서버가 1초 동안 처리할 수 있는 최대 요청 수(= 한계 TPS)를 의미하며, 즉, 서버가 초당 몇 명의 사용자를 안정적으로 처리할 수 있는지를 보여준다.
2️⃣ 특정 시나리오에서 필요한 TPS 산정하기
앞서 구한 한계 TPS를 기준으로, 이제는 특정 이벤트나 기능에서 예상되는 트래픽이 실제 서버 처리 한계에 부합하는지를 계산한다.
TPS = 1초 당 예상 요청 수 x (1000ms / 목표 응답 시간 ms)예를 들어, 특정 이벤트에서 1초 동안 300명의 사용자가 동시에 요청을 보낸다고 가정하고, 목표 응답 시간을 200ms로 설정했다면 다음과 같이 계산된다.
TPS = 300 × (1000 / 200) = 1500즉, 이 시나리오에서는 초당 약 1500건의 요청을 처리해야 한다는 의미다.
이후 현재 서버의 한계 TPS와 해당 시나리오에서 요구되는 TPS를 비교하여, 필요 시 트래픽 대응 전략(스케일링, 큐잉, 캐싱, 메시지 브로커 등)을 수립한다.
▶ 예시: 연예인 예약 공개 기능
🔽 상황

우리 서비스에서 연예인 라인업을 예약 공개하는 상황이다. 바텀 내비게이션에서 하단의 홈 탭을 클릭할 때 호출되는 API는 다음과 같다.
/api/lineups
/api/festivals즉, 한 사용자가 홈 진입 시 두 개의 API 요청이 동시에 발생하며, 이는 하나의 트랜잭션 단위로 볼 수 있다.
🔽 테스트 결과 (Local → Dev)
테스트는 300 → 500 → 1000 → 1500 → 3000 → 5000명 순으로 동시 사용자 수를 점진적으로 늘려가며 TPS가 수렴하는 구간(= 서버 한계 처리량)을 찾는 방식으로 진행했다.
🔽 스크립트
import http from 'k6/http';
import { check, sleep } from 'k6';
import { Trend, Counter } from 'k6/metrics';
const BASE_URL = '{서버_URL}';
const endpoints = ['/api/festivals', '/api/lineups'];
const params = { headers: { 헤더 값 } }; // 적절히 선택
// 시나리오별 메트릭 정의
const metrics = {
300: {
duration: new Trend('transaction_duration_300', true),
count: new Counter('transaction_count_300'),
success: new Counter('transaction_success_300'),
},
500: {
duration: new Trend('transaction_duration_500', true),
count: new Counter('transaction_count_500'),
success: new Counter('transaction_success_500'),
},
1000: {
duration: new Trend('transaction_duration_1000', true),
count: new Counter('transaction_count_1000'),
success: new Counter('transaction_success_1000'),
},
1500: {
duration: new Trend('transaction_duration_1500', true),
count: new Counter('transaction_count_1500'),
success: new Counter('transaction_success_1500'),
},
3000: {
duration: new Trend('transaction_duration_3000', true),
count: new Counter('transaction_count_3000'),
success: new Counter('transaction_success_3000'),
},
5000: {
duration: new Trend('transaction_duration_5000', true),
count: new Counter('transaction_count_5000'),
success: new Counter('transaction_success_5000'),
},
};
export const options = {
scenarios: {
step_300: { executor: 'constant-vus', vus: 300, duration: '30s', gracefulStop: '0s', exec: 'run300', startTime: '0s' },
rest_300: { executor: 'per-vu-iterations', vus: 1, iterations: 1, exec: 'rest', startTime: '30s' },
step_500: { executor: 'constant-vus', vus: 500, duration: '30s', gracefulStop: '0s', exec: 'run500', startTime: '60s' },
rest_500: { executor: 'per-vu-iterations', vus: 1, iterations: 1, exec: 'rest', startTime: '90s' },
step_1000: { executor: 'constant-vus', vus: 1000, duration: '30s', gracefulStop: '0s', exec: 'run1000', startTime: '120s' },
rest_1000: { executor: 'per-vu-iterations', vus: 1, iterations: 1, exec: 'rest', startTime: '150s' },
step_1500: { executor: 'constant-vus', vus: 1500, duration: '30s', gracefulStop: '0s', exec: 'run1500', startTime: '180s' },
rest_1500: { executor: 'per-vu-iterations', vus: 1, iterations: 1, exec: 'rest', startTime: '210s' },
step_3000: { executor: 'constant-vus', vus: 3000, duration: '30s', gracefulStop: '0s', exec: 'run3000', startTime: '240s' },
rest_3000: { executor: 'per-vu-iterations', vus: 1, iterations: 1, exec: 'rest', startTime: '270s' },
step_5000: { executor: 'constant-vus', vus: 5000, duration: '30s', gracefulStop: '0s', exec: 'run5000', startTime: '300s' },
rest_5000: { executor: 'per-vu-iterations', vus: 1, iterations: 1, exec: 'rest', startTime: '330s' },
},
thresholds: {
http_req_failed: ['rate<0.05'],
'transaction_duration_300': ['p(95)<1500'],
'transaction_duration_500': ['p(95)<1500'],
'transaction_duration_1000': ['p(95)<1500'],
'transaction_duration_1500': ['p(95)<1500'],
'transaction_duration_3000': ['p(95)<1500'],
'transaction_duration_5000': ['p(95)<1500'],
},
};
// 공통 트랜잭션 로직
function runTransaction(concurrency) {
const start = Date.now();
let success = true;
for (const path of endpoints) {
const res = http.get(`${BASE_URL}${path}`, params);
const ok = check(res, { [`${path} status 200`]: (r) => r.status === 200 });
if (!ok) success = false;
}
const duration = Date.now() - start;
metrics[concurrency].duration.add(duration);
metrics[concurrency].count.add(1);
if (success) metrics[concurrency].success.add(1);
}
// 부하 단계별 실행 함수
export function run300() { runTransaction(300); }
export function run500() { runTransaction(500); }
export function run1000() { runTransaction(1000); }
export function run1500() { runTransaction(1500); }
export function run3000() { runTransaction(3000); }
export function run5000() { runTransaction(5000); }
// 쉬는 시간 (30초 고정)
export function rest() { sleep(30); }transaction_duration_300.......: avg=1.12s min=550ms med=1.11s max=1.46s p(90)=1.23s p(95)=1.25s
transaction_duration_500.......: avg=1.82s min=969ms med=1.84s max=2.16s p(90)=1.96s p(95)=2.02s
transaction_duration_1000......: avg=3.68s min=1.04s med=3.76s max=5.15s p(90)=3.9s p(95)=3.92s
transaction_duration_1500......: avg=5.34s min=1.63s med=5.5s max=7.31s p(90)=5.6s p(95)=5.64s
transaction_duration_3000......: avg=10.24s min=3.83s med=11.17s max=22.78s p(90)=11.35s p(95)=11.38s
transaction_duration_5000......: avg=15.54s min=447ms med=15.92s max=26.05s p(90)=19.12s p(95)=19.51s
transaction_success_300........: 7804 21.676834/s
transaction_success_500........: 8000 22.221255/s
transaction_success_1000.......: 7773 21.590727/s
transaction_success_1500.......: 7508 20.854648/s
transaction_success_3000.......: 6429 17.857556/s
transaction_success_5000.......: 5306 14.738247/s| VU | 트랜잭션 수 | TPS |
| 300 | 7804 | 260.13 |
| 500 | 8000 | 266.67 |
| 1000 | 7773 | 259.10 |
| 1500 | 7508 | 250.27 |
| 3000 | 6429 | 214.30 |
| 5000 | 5306 | 176.87 |
5,000명 구간에서는 요청은 전송되었으나, 테스트 시간(30초) 내 응답이 완료되지 않아 측정된 TPS가 급격히 하락했다. 이는 서버 성능 저하가 아니라 테스트 종료로 인한 미수신 응답 누락으로 판단된다. 이를 제외하고 안정적으로 수렴한 구간을 보면, TPS는 약 250~260 수준에서 한계점에 도달하는 것으로 보인다.
🔽 결론
이후 3,000명의 학생을 보유한 모 대학교와 제휴를 체결했다고 가정하자. 현재 해당 대학교에서 약 300명이 앱을 사용 중으로 파악되며, “festabook에서 내일 오후 1시에 연예인 예약 공개” 공지가 해당 학교 인스타그램에 게시되었다. 학생들이 동시에 접속해 새로고침을 반복한다고 가정하면, 약 300명의 사용자가 1인당 평균 10회 요청을 보낸다고 예상한다. 이 요청이 5초 내에 집중적으로 발생한다고 하면, 즉 총 3,000건의 요청이 약 5초 동안 몰린다는 의미다. 이 상황에서 (그럴 일은 없겠지만) 대학교 측에서 “연예인 공개 시 응답이 0.5초 이내에 표시되도록 해달라”라고 요청했다고 가정하면, 목표 응답 시간을 0.5초(=500ms)로 설정할 수 있다. 이에 따라 필요한 TPS는 다음과 같이 계산된다.
# TPS = 1초 당 예상 요청 수 x (1000ms / 목표 응답 시간 ms)
TPS = (사용자 300명 × 10회 / 5s) × (1000ms / 500ms) = 1200즉, 5초 동안 초당 약 1,200건의 요청을 처리할 수 있어야 한다. 현재 서버의 한계 TPS는 약 250이므로, 이 부하를 대응하기 위해서는 단순히 계산상 약 5대의 서버로 Scale Out 하면 트래픽을 안정적으로 분산 처리할 수 있다.
억지로 예시에서 학생회가 응답을 0.5초 이내로 해달라고 요청했다고 가정했지만, 사실 이러한 상황에서 지연이 비즈니스적으로 치명적이지 않다면 굳이 성능을 극단적으로 개선할 필요는 없다. 중요한 것은, 문제가 예상될 때 적절한 대응 전략을 바탕으로 사전에 대비해 두는 것이다.
📍 참고 자료
- Tomcat 공식 문서 - The HTTP Connector (Attribute - Standard Implementation)
- HikariCP 공식 문서 - MySQL Configuration
- MySQL 공식 문서 - 10.12.3.1 How MySQL Uses Memory
- MySQL 공식 문서 - 17.8.3.2 Configuring Multiple Buffer Pool Instances
- OpenJDK 공식 문서 - JEP draft: Automatic Heap Sizing for G1
- John Grib GitHub - Java GC 튜닝
'Optimization' 카테고리의 다른 글
| [Optimization] 반복 조회 쿼리 개선 (14) | 2025.11.07 |
|---|